Marc-André Carbonneau

Welcome to my page!
This site contains information regarding my research and some personal projects.
I’m passionate about using the latest advances in machine learning, speech and signal processing, and visual computing to push the boundaries of video games.
I currently work as a senior research scientist at Epic Games. Before that, I acted as principal research scientist at Ubisoft in the La Forge lab between 2017 and 2025.
news
| Apr 21, 2025 | Excited to share that I’ve joined Epic Games as a Senior Research Scientist! I’m thrilled to be part of that team, and I’m looking forward to applying cutting-edge research in machine learning, speech, signal processing, and computer vision to the future of games and real-time experiences. |
|---|---|
| Apr 1, 2024 |
We are excited to share our recent work on monocular 3D face reconstruction that will be presented at CVPR 2024. We introduce MoSAR, a new method that turns a portrait image into a realistic 3D avatar.
From a single image, MoSAR estimates a detailed mesh and texture maps at 4K resolution, capturing pore-level details. This avatar can be rendered from any viewpoint and under different lighting condition. We are also releasing a new dataset called FFHQ-UV-Intrinsics. This is the first dataset that offer rich intrinsic face attributes (diffuse, specular, ambient occlusion and translucency) at high resolution for 10K subjects. Check out the project page! |
| Oct 27, 2023 |
Our paper EDMSound: Spectrogram Based Diffusion Models for Efficient and High-Quality Audio Synthesis has been accepted for presentation at the NeurIPS Workshop on ML for Audio. This work has been done in collaboration with colleagues from Rochester University.
In this paper, we propose a diffusion-based generative model in spectrogram domain under the framework of elucidated diffusion models (EDM). We also revealed a potential concern regarding diffusion based audio generation models that they tend to generate duplication of the training data. Check out the project page! |
| Sep 21, 2023 |
Our paper “Rhythm Modeling for Voice Conversion” has been published in IEEE Signal Processing Letters. We also released it on Arxiv.
In this paper we model the natural rhythm of speakers to perform conversion while respecting the target speaker’s natural rhythm. We do more than approximating the global speech rate, we model duration for sonorants, obstruents, and silences. Check out the demo page! |
| Jul 15, 2023 |
Ubisoft had published a blog page describing our system for gesture generation conditioned on speech.
This system was presented in “ZeroEGGS: Zero-shot Example-based Gesture Generation from Speech” and showcased on 2 minute papers. |
selected publications
-
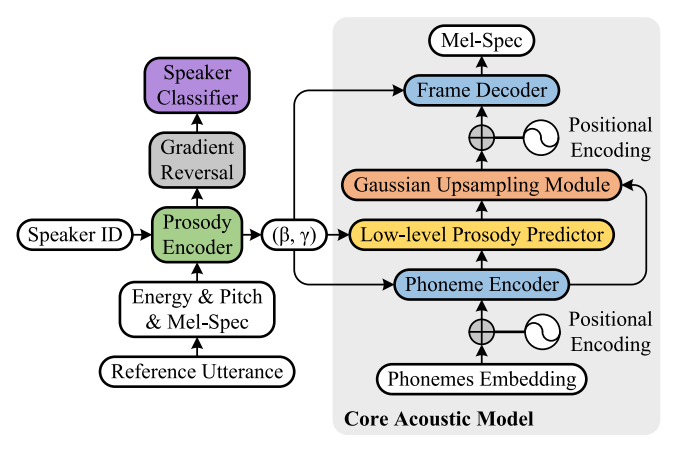 Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech SynthesisIn INTERSPEECH, 2022
Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech SynthesisIn INTERSPEECH, 2022 -
Multiple instance learning: A survey of problem characteristics and applicationsPattern Recognition, 2018
-










